


Intel TSNC: compresión de texturas con IA que promete hasta 18x menos tamaño
Intel acaba de compartir nuevos detalles sobre su tecnología de compresión de texturas con inteligencia artificial, bautizada como Texture Set Neural Compression (TSNC). Aunque debutó como una demo de investigación de Intel Labs en el GDC 2025, la compañía anuncia ahora que el proyecto fue reconstruido como un SDK independiente, con una nueva API de descompresión que puede compilar a C, C++ o HLSL.

Dos variantes, dos niveles de compresión
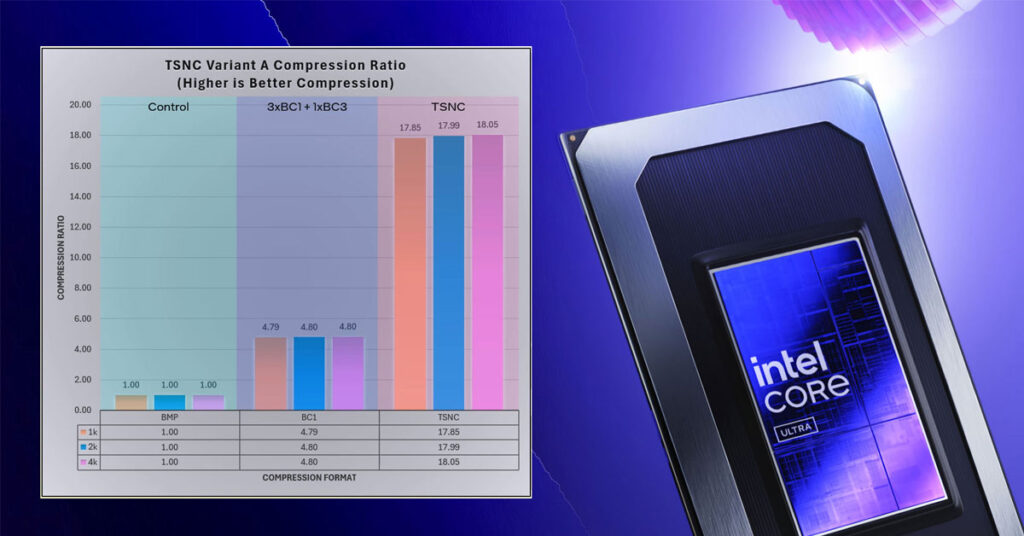
La idea central de TSNC es superar la compresión de bloques estándar entrenando una red neuronal para codificar y decodificar un conjunto de texturas de forma conjunta. Intel almacena los datos latentes en una pirámide de características de cuatro capas basada en BC1, y luego reconstruye los canales de textura originales mediante un decoder MLP de tres capas. Según la empresa, esto permite ahorrar almacenamiento, ancho de banda de memoria o VRAM, dependiendo del caso de uso: descompresión en tiempo de instalación, al cargar, streaming o muestreo por píxel en tiempo real.


Intel probó dos modos denominados Variante A y Variante B. La compresión BC estándar logró aproximadamente una ratio de 4,8x frente al conjunto de control de mapa de bits. La Variante A superó ese umbral con más de 9x de compresión, manteniendo mejor calidad de imagen. La Variante B fue más agresiva, alcanzando más de 18x de compresión, el doble de reducción que la Variante A y que la compresión de bloques convencional en esa misma prueba.


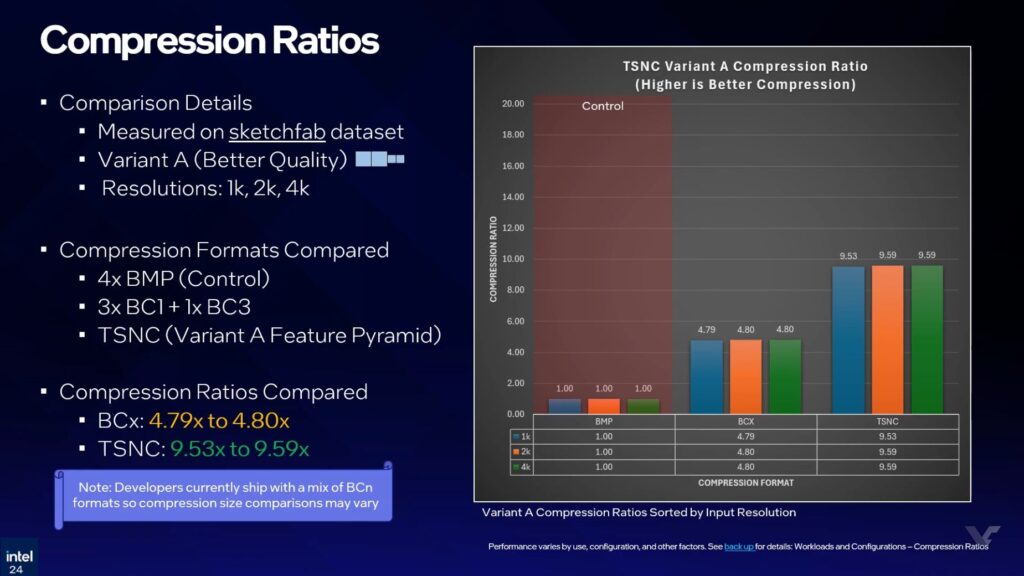

Esa mayor compresión no es gratuita: la Variante A introduce cierta pérdida de precisión en los mapas de normales, mientras que la Variante B empieza a mostrar artefactos BC1 en normales y datos ARM. En el análisis perceptual realizado con la herramienta FLIP de NVIDIA, Intel estimó una pérdida perceptual de alrededor del 5% para la Variante A y de entre el 6% y 7% para la Variante B. La Variante A se presenta como la opción equilibrada; la B, como la de máxima compresión.
Rendimiento en Panther Lake y aceleración XMX
Intel publicó además un microbenchmark ejecutado sobre los gráficos integrados B390 de Panther Lake. La ruta de retroceso FMA promedió unos 0,661 nanosegundos por píxel, mientras que la ruta de álgebra lineal promedió 0,194 nanosegundos por píxel; una aceleración de aproximadamente 3,4x según la propia empresa. El decodificador admite ambas rutas: una de respaldo fused multiply-add para CPU y GPU, y otra de álgebra lineal que aprovecha la aceleración XMX en las GPUs Intel compatibles.
Intel encuadra a TSNC dentro de la misma tendencia que NVIDIA, que en su propia charla del GDC mencionó compresiones de hasta el 85%. De cara al futuro, habrá que ver cómo avanza la adopción: Intel planea lanzar un alpha SDK antes de que termine el año, seguido de una fase beta y posteriormente una versión pública.
Fuente: VideoCardz


